理解决策框架
在使用 CrewAI 构建 AI 应用程序时,最重要的决策之一是为您的特定用例选择正确的方法。您应该使用 Crew 吗?还是 Flow?或者两者结合?本指南将帮助您评估您的需求并做出明智的架构决策。 这个决策的核心在于理解应用程序中**复杂性**和**精确度**之间的关系: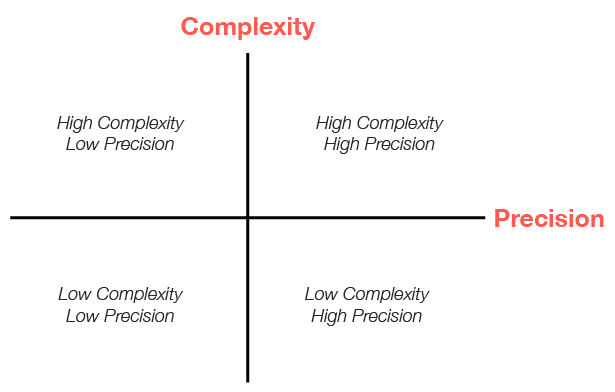
CrewAI 应用程序的复杂性与精确度矩阵
复杂性-精确度矩阵解释
什么是复杂性?
在 CrewAI 应用程序的上下文中,**复杂性**指的是:- 所需的不同步骤或操作的数量
- 需要执行的任务的多样性
- 不同组件之间的相互依赖性
- 对条件逻辑和分支的需求
- 整体工作流的复杂程度
什么是精确度?
此上下文中的**精确度**指的是:- 最终输出所需的准确性
- 对结构化、可预测结果的需求
- 可重现性的重要性
- 对每个步骤所需控制的程度
- 输出变化的容忍度
四个象限
1. 低复杂性,低精确度
特点- 简单、直接的任务
- 对输出的一些变化具有容忍度
- 步骤数量有限
- 创意或探索性应用
- 基本内容生成
- 头脑风暴
- 简单总结任务
- 创意写作辅助
2. 低复杂性,高精确度
特点- 需要精确、结构化输出的简单工作流
- 需要可重现的结果
- 步骤有限但准确性要求高
- 通常涉及数据处理或转换
- 数据提取和转换
- 表单填写和验证
- 结构化内容生成(JSON、XML)
- 简单分类任务
3. 高复杂性,低精确度
特点- 具有多个步骤的多阶段流程
- 创意或探索性输出
- 组件之间复杂的交互
- 最终结果变化的容忍度
- 研究与分析
- 内容创建管道
- 探索性数据分析
- 创造性问题解决
4. 高复杂性,高精确度
特点- 需要结构化输出的复杂工作流
- 具有严格准确性要求的多个相互依赖的步骤
- 需要复杂的处理和精确的结果
- 通常是任务关键型应用程序
- 企业决策支持系统
- 复杂数据处理管道
- 多阶段文档处理
- 受监管的行业应用
在 Crews 和 Flows 之间选择
何时选择 Crews
Crew 在以下情况下是理想选择:- **您需要协作智能** - 多个具有不同专业知识的智能体需要协同工作
- **问题需要涌现思维** - 解决方案受益于不同的视角和方法
- **任务主要是创造性或分析性的** - 工作涉及研究、内容创建或分析
- **您重视适应性而非严格结构** - 工作流可以受益于智能体的自主性
- **输出格式可以相对灵活** - 允许输出结构存在一些变化
何时选择 Flows
Flow 在以下情况下是理想选择:- **您需要精确控制执行** - 工作流需要精确的序列和状态管理
- **应用程序具有复杂的状态要求** - 您需要在多个步骤中维护和转换状态
- **您需要结构化、可预测的输出** - 应用程序需要一致、格式化的结果
- **工作流涉及条件逻辑** - 需要根据中间结果采取不同的路径
- **您需要将 AI 与过程代码结合** - 解决方案需要 AI 功能和传统编程
何时结合 Crews 和 Flows
最复杂的应用程序通常受益于结合 Crews 和 Flows- **复杂的多阶段流程** - 使用 Flow 编排整体流程,并使用 Crew 处理复杂的子任务
- **需要创造性和结构的应用程序** - 使用 Crew 进行创造性任务,使用 Flow 进行结构化处理
- **企业级 AI 应用程序** - 使用 Flow 管理状态和流程,同时利用 Crew 进行专业工作
实用评估框架
要确定您的特定用例的正确方法,请遵循此分步评估框架步骤 1:评估复杂性
通过考虑以下因素,将您的应用程序的复杂性评分为 1-10:-
**步骤数**:需要多少个不同的操作?
- 1-3 个步骤:低复杂性 (1-3)
- 4-7 个步骤:中等复杂性 (4-7)
- 8+ 个步骤:高复杂性 (8-10)
-
**相互依赖性**:不同部分之间的相互关联程度如何?
- 很少依赖:低复杂性 (1-3)
- 一些依赖:中等复杂性 (4-7)
- 许多复杂依赖:高复杂性 (8-10)
-
**条件逻辑**:需要多少分支和决策?
- 线性流程:低复杂性 (1-3)
- 一些分支:中等复杂性 (4-7)
- 复杂决策树:高复杂性 (8-10)
-
**领域知识**:所需的知识有多专业?
- 一般知识:低复杂性 (1-3)
- 一些专业知识:中等复杂性 (4-7)
- 多个领域的深厚专业知识:高复杂性 (8-10)
步骤 2:评估精确度要求
通过考虑以下因素,将您的精确度要求评分为 1-10:-
**输出结构**:输出必须有多结构化?
- 自由形式文本:低精确度 (1-3)
- 半结构化:中等精确度 (4-7)
- 严格格式化(JSON、XML):高精确度 (8-10)
-
**准确性需求**:事实准确性有多重要?
- 创意内容:低精确度 (1-3)
- 信息内容:中等精确度 (4-7)
- 关键信息:高精确度 (8-10)
-
**可重现性**:结果在不同运行中必须有多一致?
- 可接受变动:低精确度 (1-3)
- 需要一定的一致性:中等精确度 (4-7)
- 需要精确的可重现性:高精确度 (8-10)
-
**错误容忍度**:错误的影响是什么?
- 低影响:低精确度 (1-3)
- 中等影响:中等精确度 (4-7)
- 高影响:高精确度 (8-10)
步骤 3:映射到矩阵
将您的复杂性和精确度分数绘制在矩阵上- **低复杂性 (1-4),低精确度 (1-4)**:简单 Crew
- **低复杂性 (1-4),高精确度 (5-10)**:直接调用 LLM 的 Flow
- **高复杂性 (5-10),低精确度 (1-4)**:复杂 Crew
- **高复杂性 (5-10),高精确度 (5-10)**:编排 Crew 的 Flow
步骤 4:考虑附加因素
除了复杂性和精确度之外,还要考虑:- **开发时间**:Crew 通常原型化速度更快
- **维护需求**:Flow 提供更好的长期可维护性
- **团队专业知识**:考虑您的团队对不同方法的熟悉程度
- **可伸缩性要求**:Flow 通常更适合复杂应用程序的扩展
- **集成需求**:考虑解决方案将如何与现有系统集成
结论
在 Crew 和 Flow 之间选择(或结合它们)是一个关键的架构决策,它会影响 CrewAI 应用程序的有效性、可维护性和可伸缩性。通过沿着复杂性和精确度维度评估您的用例,您可以做出符合您特定要求的明智决策。 请记住,最佳方法通常会随着应用程序的成熟而演变。从最简单的解决方案开始,以满足您的需求,并准备好随着您获得经验和需求变得更清晰而完善您的架构。您现在拥有一个评估 CrewAI 用例并根据复杂性和精确度要求选择正确方法的框架。这将帮助您构建更有效、可维护和可扩展的 AI 应用程序。
后续步骤
- 了解更多关于设计有效智能体的信息
- 探索构建您的第一个 Crew
- 深入了解掌握 Flow 状态管理
- 查看核心概念以获得更深入的理解