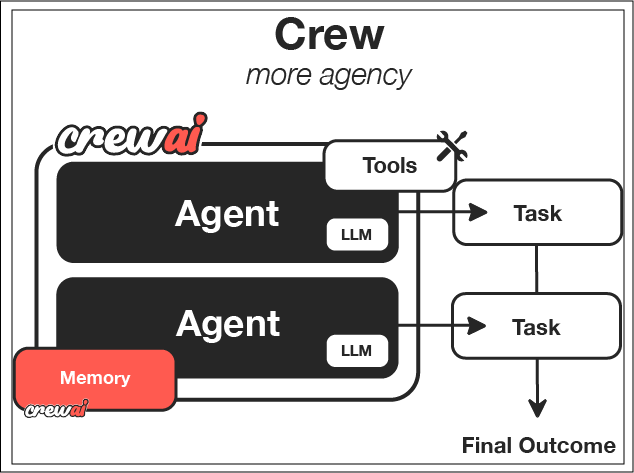
释放协同 AI 的力量
想象一下,一个由专业 AI 代理组成的团队无缝协作,共同解决复杂问题,每个代理都贡献其独特的技能以实现共同目标。这就是 CrewAI 的力量——一个使您能够创建协同 AI 系统的框架,这些系统能够完成单个 AI 无法独立完成的任务。 在本指南中,我们将逐步创建一个研究团队,该团队将帮助我们研究和分析一个主题,然后创建一份全面的报告。这个实际示例展示了 AI 代理如何协作完成复杂任务,但这仅仅是 CrewAI 可能实现的开端。你将构建和学习什么
在本指南结束时,你将
- 创建了一个专业的 AI 研究团队,具有明确的角色和职责
- 协调多个 AI 代理之间的协作
- 自动化了一个涉及信息收集、分析和报告生成的复杂工作流程
- 建立了可应用于更宏大项目的基本技能
虽然我们在此指南中构建了一个简单的研究团队,但相同的模式和技术可以应用于创建更复杂的团队,以完成以下任务:
- 多阶段内容创作,由专业作家、编辑和事实核查员组成
- 复杂客户服务系统,具有分级支持代理
- 自主商业分析师,负责收集数据、创建可视化并生成洞察
- 产品开发团队,负责构思、设计和规划实施
让我们开始构建你的第一个团队吧!
先决条件
开始之前,请确保你已经
- 按照安装指南安装了 CrewAI
- 按照LLM 设置指南在你的环境中设置了 LLM API 密钥
- 对 Python 有基本了解
步骤 1:创建一个新的 CrewAI 项目
首先,让我们使用 CLI 创建一个新的 CrewAI 项目。此命令将设置一个完整的项目结构,包含所有必要的文件,让您能够专注于定义代理及其任务,而不是设置样板代码。
crewai create crew research_crew
cd research_crew
- 一个包含必要文件的项目目录
- 代理和任务的配置文件
- 一个基本的团队实现
- 一个运行团队的主脚本
步骤 2:探索项目结构
让我们花点时间了解一下 CLI 创建的项目结构。CrewAI 遵循 Python 项目的最佳实践,让您的团队变得更复杂时,代码也易于维护和扩展。
research_crew/
├── .gitignore
├── pyproject.toml
├── README.md
├── .env
└── src/
└── research_crew/
├── __init__.py
├── main.py
├── crew.py
├── tools/
│ ├── custom_tool.py
│ └── __init__.py
└── config/
├── agents.yaml
└── tasks.yaml
- 一个擅长查找和组织信息的研究员
- 一个能够解读研究结果并创建富有洞察力报告的分析师
让我们修改 agents.yaml 文件来定义这些专业代理。请务必将 llm 设置为您正在使用的提供商。
# src/research_crew/config/agents.yaml
researcher:
role: >
Senior Research Specialist for {topic}
goal: >
Find comprehensive and accurate information about {topic}
with a focus on recent developments and key insights
backstory: >
You are an experienced research specialist with a talent for
finding relevant information from various sources. You excel at
organizing information in a clear and structured manner, making
complex topics accessible to others.
llm: provider/model-id # e.g. openai/gpt-4o, google/gemini-2.0-flash, anthropic/claude...
analyst:
role: >
Data Analyst and Report Writer for {topic}
goal: >
Analyze research findings and create a comprehensive, well-structured
report that presents insights in a clear and engaging way
backstory: >
You are a skilled analyst with a background in data interpretation
and technical writing. You have a talent for identifying patterns
and extracting meaningful insights from research data, then
communicating those insights effectively through well-crafted reports.
llm: provider/model-id # e.g. openai/gpt-4o, google/gemini-2.0-flash, anthropic/claude...
步骤 4:定义你的任务
在定义了我们的代理之后,我们现在需要给它们分配特定的任务。CrewAI 中的任务代表代理将执行的具体工作,包含详细的指令和预期输出。 对于我们的研究团队,我们将定义两个主要任务:
- 一个用于收集全面信息的研究任务
- 一个用于创建富有洞察力报告的分析任务
让我们修改 tasks.yaml 文件
# src/research_crew/config/tasks.yaml
research_task:
description: >
Conduct thorough research on {topic}. Focus on:
1. Key concepts and definitions
2. Historical development and recent trends
3. Major challenges and opportunities
4. Notable applications or case studies
5. Future outlook and potential developments
Make sure to organize your findings in a structured format with clear sections.
expected_output: >
A comprehensive research document with well-organized sections covering
all the requested aspects of {topic}. Include specific facts, figures,
and examples where relevant.
agent: researcher
analysis_task:
description: >
Analyze the research findings and create a comprehensive report on {topic}.
Your report should:
1. Begin with an executive summary
2. Include all key information from the research
3. Provide insightful analysis of trends and patterns
4. Offer recommendations or future considerations
5. Be formatted in a professional, easy-to-read style with clear headings
expected_output: >
A polished, professional report on {topic} that presents the research
findings with added analysis and insights. The report should be well-structured
with an executive summary, main sections, and conclusion.
agent: analyst
context:
- research_task
output_file: output/report.md
context 字段——这是一个强大的功能,它允许分析师访问研究任务的输出。这创建了一个信息在代理之间自然流动的流程,就像在人类团队中一样。
现在是时候通过配置我们的团队来将所有内容整合起来了。团队是协调代理如何协同完成任务的容器。 让我们修改 crew.py 文件:# src/research_crew/crew.py
from crewai import Agent, Crew, Process, Task
from crewai.project import CrewBase, agent, crew, task
from crewai_tools import SerperDevTool
from crewai.agents.agent_builder.base_agent import BaseAgent
from typing import List
@CrewBase
class ResearchCrew():
"""Research crew for comprehensive topic analysis and reporting"""
agents: List[BaseAgent]
tasks: List[Task]
@agent
def researcher(self) -> Agent:
return Agent(
config=self.agents_config['researcher'], # type: ignore[index]
verbose=True,
tools=[SerperDevTool()]
)
@agent
def analyst(self) -> Agent:
return Agent(
config=self.agents_config['analyst'], # type: ignore[index]
verbose=True
)
@task
def research_task(self) -> Task:
return Task(
config=self.tasks_config['research_task'] # type: ignore[index]
)
@task
def analysis_task(self) -> Task:
return Task(
config=self.tasks_config['analysis_task'], # type: ignore[index]
output_file='output/report.md'
)
@crew
def crew(self) -> Crew:
"""Creates the research crew"""
return Crew(
agents=self.agents,
tasks=self.tasks,
process=Process.sequential,
verbose=True,
)
- 创建研究员代理并为其配备 SerperDevTool 以进行网络搜索
- 创建分析师代理
- 设置研究和分析任务
- 配置团队按顺序运行任务(分析师将等待研究员完成)
这就是奇迹发生的地方——只需几行代码,我们就定义了一个协同 AI 系统,其中专业代理以协调一致的过程协同工作。
步骤 6:设置你的主脚本
现在,让我们设置运行我们团队的主脚本。在这里,我们提供我们希望团队研究的特定主题。
#!/usr/bin/env python
# src/research_crew/main.py
import os
from research_crew.crew import ResearchCrew
# Create output directory if it doesn't exist
os.makedirs('output', exist_ok=True)
def run():
"""
Run the research crew.
"""
inputs = {
'topic': 'Artificial Intelligence in Healthcare'
}
# Create and run the crew
result = ResearchCrew().crew().kickoff(inputs=inputs)
# Print the result
print("\n\n=== FINAL REPORT ===\n\n")
print(result.raw)
print("\n\nReport has been saved to output/report.md")
if __name__ == "__main__":
run()
步骤 7:设置你的环境变量
在你的项目根目录中创建一个 .env 文件,其中包含你的 API 密钥
SERPER_API_KEY=your_serper_api_key
# Add your provider's API key here too.
步骤 8:安装依赖项
使用 CrewAI CLI 安装所需的依赖项
此命令将
- 从您的项目配置中读取依赖项
- 如果需要,创建虚拟环境
- 安装所有必需的包
步骤 9:运行你的团队
现在激动人心的时刻到了——是时候运行你的团队,亲眼目睹 AI 协作的魅力了!
当你运行此命令时,你的团队将活跃起来。研究员将收集关于指定主题的信息,然后分析师将根据该研究创建一份全面的报告。在它们协同完成任务时,你将实时看到代理的思维过程、行动和输出。
步骤 10:审查输出
团队完成工作后,你将在 output/report.md 文件中找到最终报告。报告将包含:
- 执行摘要
- 关于主题的详细信息
- 分析和见解
- 建议或未来考量
花点时间体会你所完成的成就——你创建了一个系统,其中多个 AI 代理协作完成一项复杂的任务,每个代理都贡献其专业技能,以产生比任何单个代理单独完成的成果更强大的结果。
探索其他 CLI 命令
CrewAI 提供了其他几个有用的 CLI 命令,用于与团队协作
# View all available commands
crewai --help
# Run the crew
crewai run
# Test the crew
crewai test
# Reset crew memories
crewai reset-memories
# Replay from a specific task
crewai replay -t <task_id>
可能性艺术:超越你的第一个团队
你在这个指南中构建的仅仅是个开始。你学到的技能和模式可以应用于创建越来越复杂的 AI 系统。以下是你如何扩展这个基本研究团队的一些方法:
扩展你的团队
你可以为你的团队添加更多专业的代理
- 一个事实核查员来验证研究结果
- 一个数据可视化师来创建图表
- 一个在特定领域具有专业知识的领域专家
- 一个评论员来找出分析中的弱点
你可以通过额外的工具增强你的代理
- 用于实时研究的网络浏览工具
- 用于数据分析的 CSV/数据库工具
- 用于数据处理的代码执行工具
- 连接到外部服务的 API
创建更复杂的工作流程
你可以实现更复杂的流程
- 层级流程,其中经理代理委派给工作代理
- 带有反馈循环的迭代流程,用于改进
- 并行流程,其中多个代理同时工作
- 根据中间结果进行调整的动态流程
应用于不同领域
同样的模式可以应用于创建用于以下领域的团队:
- 内容创作:作家、编辑、事实核查员和设计师协同工作
- 客户服务:分流代理、专家和质量控制协同工作
- 产品开发:研究员、设计师和规划师协作
- 数据分析:数据收集员、分析师和可视化专家
后续步骤
现在你已经构建了你的第一个团队,你可以
- 尝试不同的代理配置和个性
- 尝试更复杂的任务结构和工作流程
- 实施自定义工具以赋予您的代理新功能
- 将您的团队应用于不同的主题或问题领域
- 探索CrewAI Flows以获取更高级的程序化工作流程
恭喜!您已成功构建您的第一个 CrewAI 团队,该团队可以研究和分析您提供的任何主题。这一基础经验使您掌握了创建日益复杂的 AI 系统的技能,这些系统可以通过协作智能解决复杂、多阶段的问题。