概述
CrewAI Flows 是一个强大的功能,旨在简化 AI 工作流的创建和管理。Flows 允许开发者高效地组合和协调编码任务与智能体,为构建复杂的 AI 自动化提供了一个强大的框架。 Flows 允许您创建结构化、事件驱动的工作流。它们提供了一种无缝连接多个任务、管理状态和控制 AI 应用程序执行流的方式。借助 Flows,您可以轻松设计和实现多步骤流程,充分利用 CrewAI 的全部功能。- 简化的工作流创建:轻松地将多个智能体和任务链接在一起,以创建复杂的 AI 工作流。
- 状态管理:Flows 使您的工作流中的不同任务之间管理和共享状态变得超级容易。
- 事件驱动架构:建立在事件驱动模型之上,实现动态和响应式工作流。
- 灵活的控制流:在您的工作流中实现条件逻辑、循环和分支。
开始入门
让我们创建一个简单的流程,您将在一个任务中使用 OpenAI 生成一个随机城市,然后使用该城市在另一个任务中生成一个有趣的事实。代码
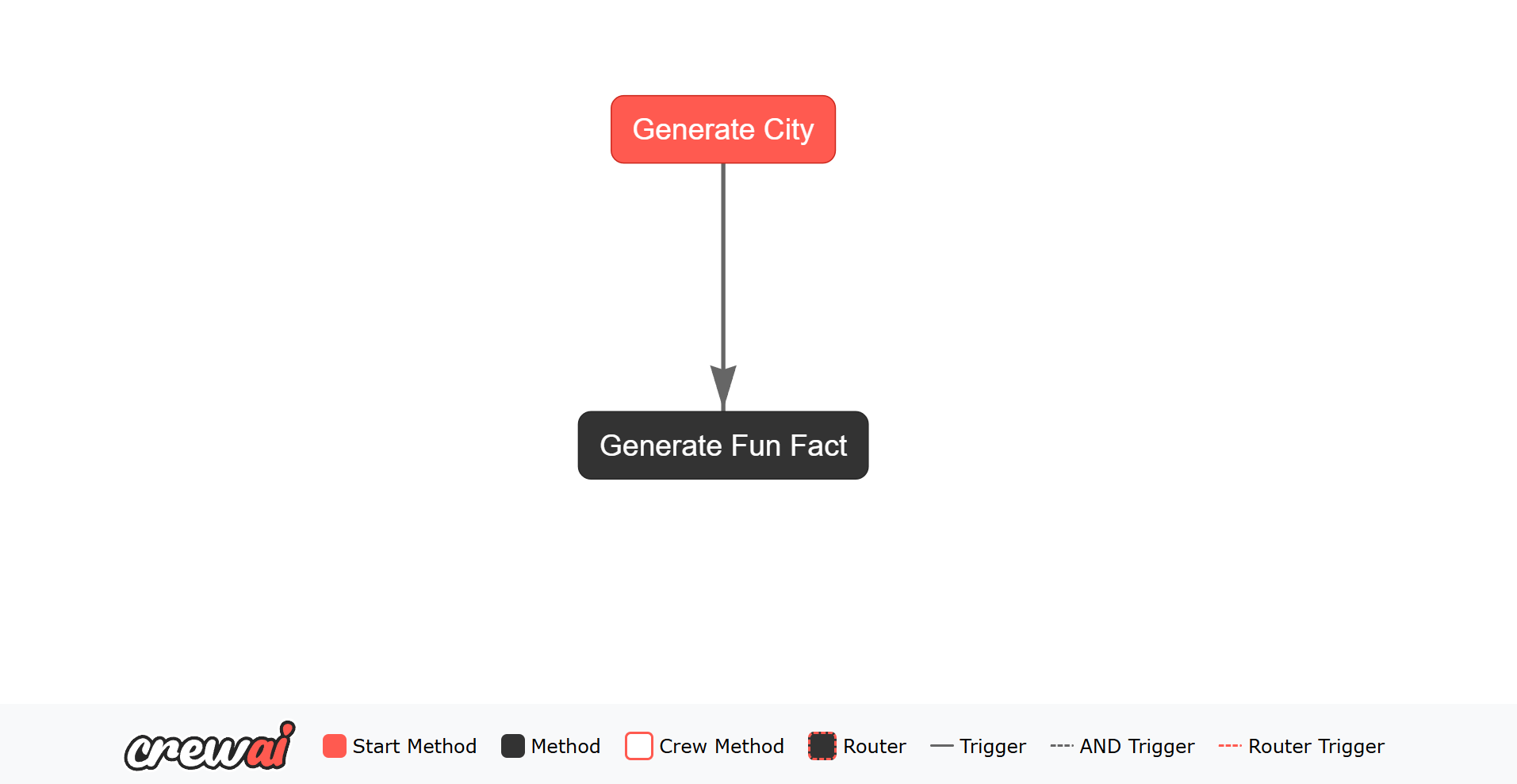
generate_city 和 generate_fun_fact。generate_city 任务是流程的起点,而 generate_fun_fact 任务监听 generate_city 任务的输出。 每个流程实例会自动在其状态中接收一个唯一标识符(UUID),这有助于跟踪和管理流程执行。状态还可以存储在流程执行期间持续存在的额外数据(如生成的城市和有趣事实)。 当您运行流程时,它将:- 为流状态生成一个唯一的 ID
- 生成一个随机城市并将其存储在状态中
- 生成关于该城市的有趣事实并将其存储在状态中
- 将结果打印到控制台
.env 文件以存储您的 OPENAI_API_KEY。此密钥对于向 OpenAI API 进行身份验证请求是必需的。@start()
@start() 装饰器标记流程的入口点。您可以:
- 声明多个无条件启动:
@start() - 通过先前的函数或路由器标签来启动:
@start("method_or_label") - 提供一个可调用条件来控制何时启动
@start() 方法将在流程开始或恢复时执行(通常是并行执行)。
@listen()
@listen() 装饰器用于将一个方法标记为监听流程中另一个任务的输出。使用 @listen() 装饰器装饰的方法将在指定任务发出输出时执行。该方法可以作为参数访问其监听的任务的输出。
用法
@listen() 装饰器可以通过多种方式使用:
-
按名称监听方法:您可以将要监听的方法的名称作为字符串传递。当该方法完成时,监听器方法将被触发。
代码
-
直接监听方法:您可以直接传递方法本身。当该方法完成时,监听器方法将被触发。
代码
流程输出
访问和处理流程的输出对于将您的 AI 工作流集成到更大的应用程序或系统中至关重要。CrewAI Flows 提供了直接的机制来检索最终输出,访问中间结果,并管理流程的整体状态。检索最终输出
当您运行一个流程时,最终输出由最后一个完成的方法决定。kickoff() 方法返回此最终方法的输出。 以下是访问最终输出的方法: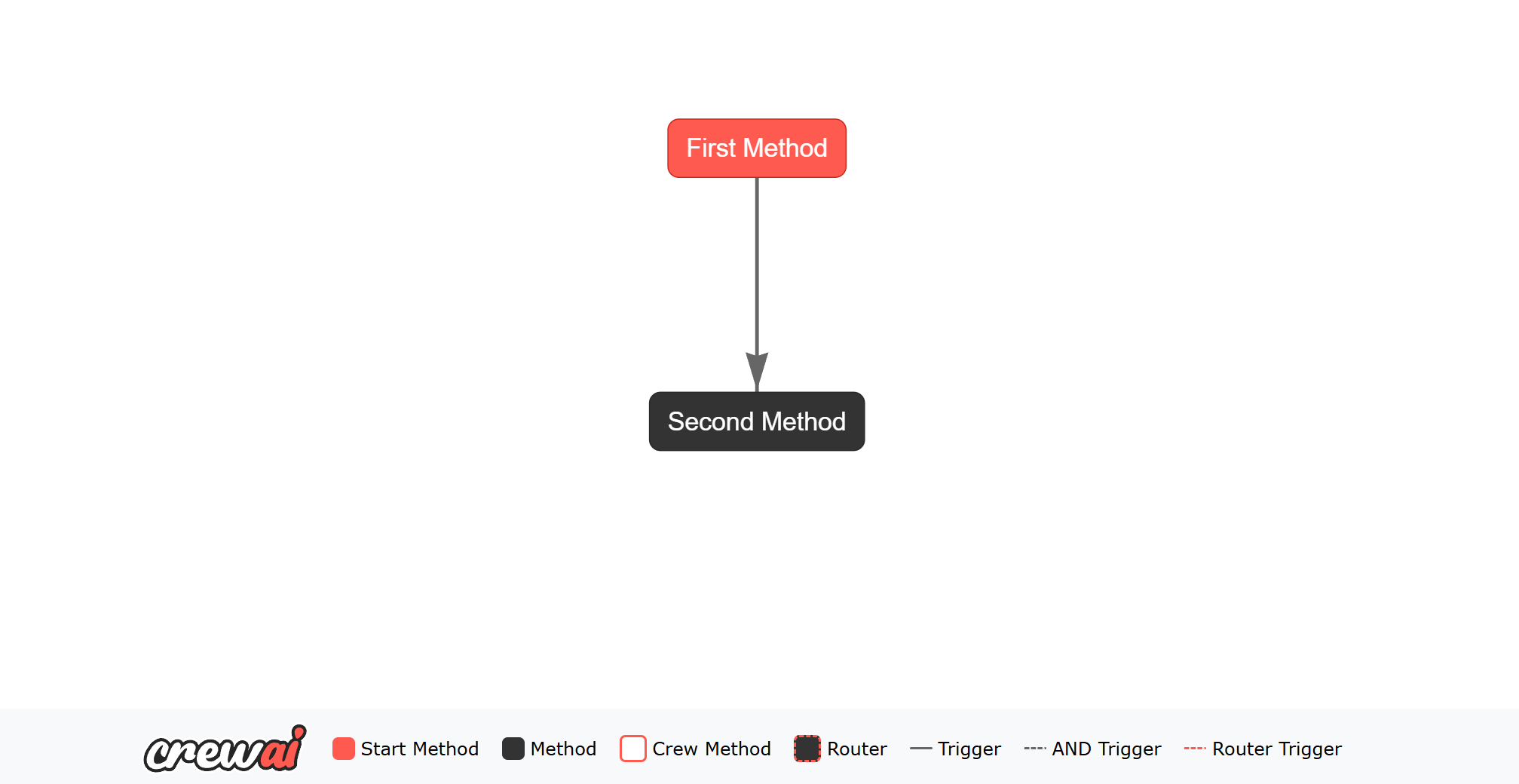
second_method 是最后一个完成的方法,因此其输出将是流程的最终输出。kickoff() 方法将返回最终输出,然后将其打印到控制台。plot() 方法将生成 HTML 文件,这将帮助您理解流程。访问和更新状态
除了检索最终输出,您还可以访问和更新流程中的状态。状态可用于在流程中存储和共享不同方法之间的数据。流程运行后,您可以访问状态以检索在执行期间添加或更新的任何信息。 以下是如何更新和访问状态的示例:first_method 和 second_method 都更新了状态。流程运行后,您可以访问最终状态以查看这些方法所做的更新。 通过确保返回最终方法的输出并提供对状态的访问,CrewAI Flows 使得将 AI 工作流的结果集成到更大的应用程序或系统中变得容易,同时在流程执行过程中维护和访问状态。流状态管理
有效管理状态对于构建可靠且可维护的 AI 工作流至关重要。CrewAI Flows 提供了强大的非结构化和结构化状态管理机制,允许开发者选择最适合其应用程序需求的方法。非结构化状态管理
在非结构化状态管理中,所有状态都存储在Flow 类的 state 属性中。这种方法提供了灵活性,使开发者能够即时添加或修改状态属性,而无需定义严格的模式。即使是非结构化状态,CrewAI Flows 也会自动为每个状态实例生成和维护一个唯一标识符(UUID)。
代码
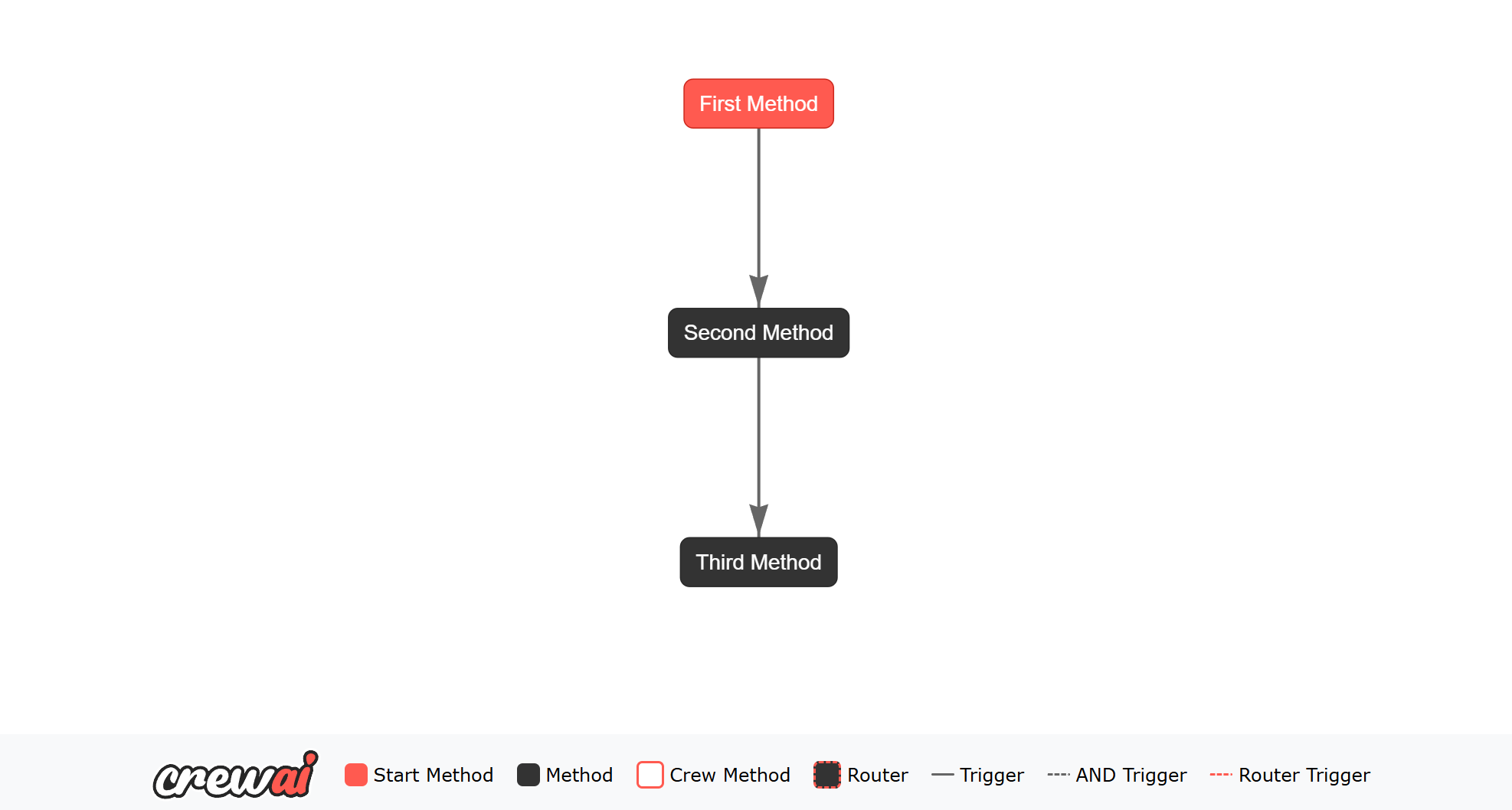
id 字段会自动生成并在流程执行过程中保留。您无需手动管理或设置它,即使使用新数据更新状态,它也会被维护。 要点:- 灵活性:您可以动态地向
self.state添加属性,而无需预定义的限制。 - 简单性:适用于状态结构最小或变化很大的直接工作流。
结构化状态管理
结构化状态管理利用预定义的模式来确保整个工作流的一致性和类型安全。通过使用 Pydantic 的BaseModel 等模型,开发者可以定义状态的确切形状,从而在开发环境中实现更好的验证和自动补全。 CrewAI Flows 中的每个状态都会自动接收一个唯一标识符 (UUID),以帮助跟踪和管理状态实例。此 ID 由流程系统自动生成和管理。代码
- 已定义模式:
ExampleState清晰地勾勒了状态结构,增强了代码的可读性和可维护性。 - 类型安全:利用 Pydantic 确保状态属性符合指定的类型,减少运行时错误。
- 自动补全:IDE 可以根据定义的状态模型提供更好的自动补全和错误检查。
非结构化与结构化状态管理的选择
-
在以下情况下使用非结构化状态管理:
- 工作流的状态简单或高度动态。
- 灵活性优先于严格的状态定义。
- 需要快速原型设计,无需定义模式的开销。
-
在以下情况下使用结构化状态管理:
- 工作流需要定义良好且一致的状态结构。
- 类型安全和验证对于应用程序的可靠性很重要。
- 您希望利用 IDE 功能(如自动补全和类型检查)以获得更好的开发人员体验。
流程持久性
@persist 装饰器在 CrewAI Flows 中启用自动状态持久性,允许您在重启或不同工作流执行中维护流状态。此装饰器可以应用于类级别或方法级别,从而在管理状态持久性方面提供了灵活性。类级别持久性
当应用于类级别时,@persist 装饰器会自动持久化所有流方法状态方法级持久性
为了更精细的控制,您可以将 @persist 应用于特定的方法工作原理
-
唯一状态标识
- 每个流状态都会自动接收一个唯一的 UUID
- ID 在状态更新和方法调用中都会保留
- 支持结构化(Pydantic BaseModel)和非结构化(字典)状态
-
默认 SQLite 后端
- SQLiteFlowPersistence 是默认存储后端
- 状态会自动保存到本地 SQLite 数据库
- 强大的错误处理确保数据库操作失败时有清晰的消息
-
错误处理
- 数据库操作的全面错误消息
- 在保存和加载期间自动验证状态
- 当持久化操作遇到问题时提供清晰的反馈
重要注意事项
- 状态类型:支持结构化(Pydantic BaseModel)和非结构化(字典)状态
- 自动 ID:如果不存在,则会自动添加
id字段 - 状态恢复:失败或重启的流程可以自动重新加载其先前的状态
- 自定义实现:您可以为特殊的存储需求提供自己的 FlowPersistence 实现
技术优势
-
通过低级访问实现精确控制
- 直接访问持久化操作以应对高级用例
- 通过方法级持久化装饰器进行精细控制
- 内置状态检查和调试功能
- 完全可见状态更改和持久化操作
-
增强的可靠性
- 系统故障或重启后自动恢复状态
- 基于事务的状态更新以确保数据完整性
- 全面的错误处理,并附带清晰的错误消息
- 在状态保存和加载操作期间进行强大的验证
-
可扩展架构
- 通过 FlowPersistence 接口定制持久性后端
- 支持 SQLite 之外的专用存储解决方案
- 兼容结构化 (Pydantic) 和非结构化 (dict) 状态
- 与现有 CrewAI 流程模式无缝集成
流程控制
条件逻辑:or
Flows 中的 or_ 函数允许您监听多个方法,并在其中任何一个方法发出输出时触发监听器方法。
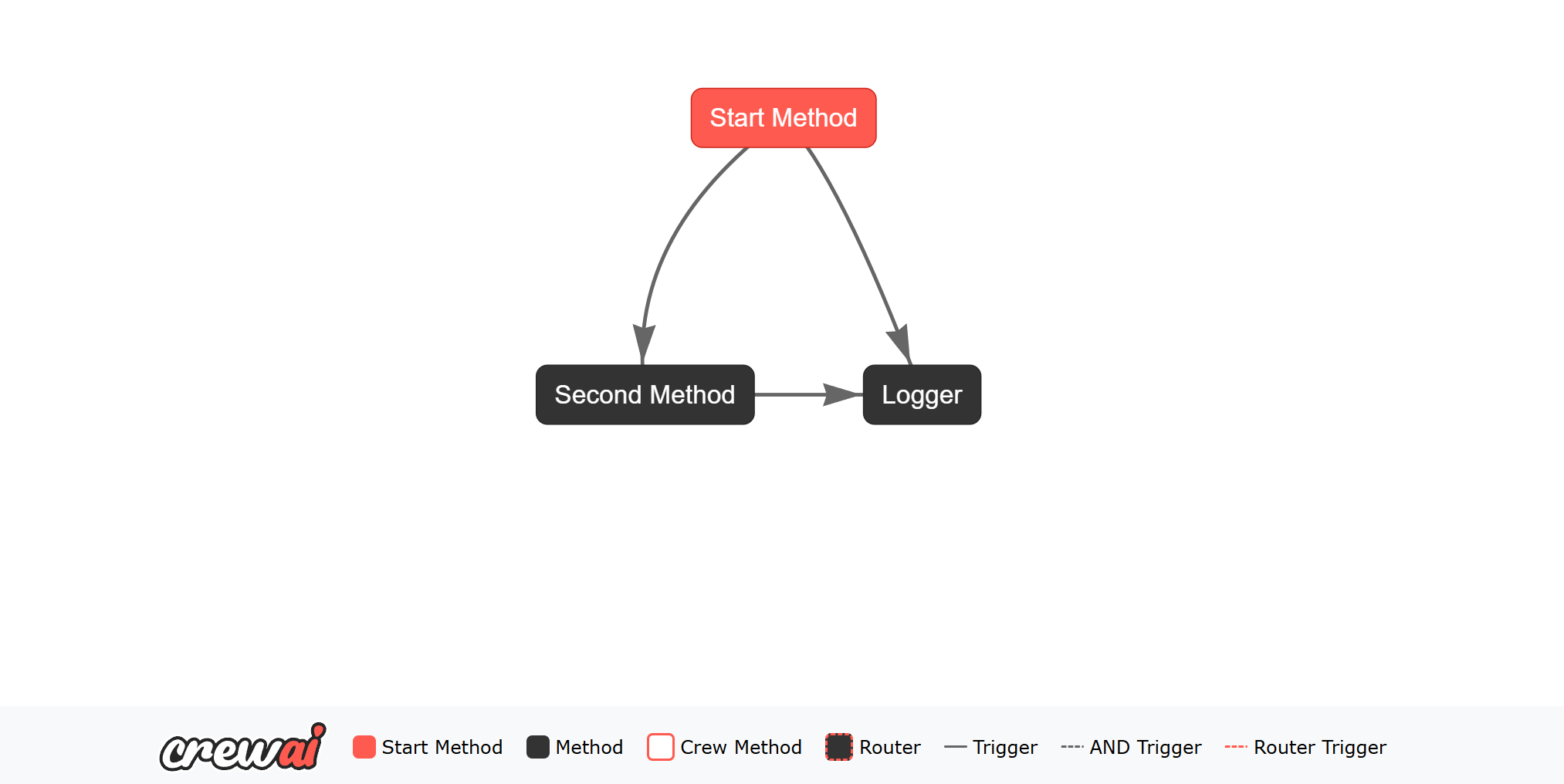
logger 方法将由 start_method 或 second_method 的输出触发。or_ 函数用于监听多个方法,并在任何指定方法发出输出时触发监听器方法。条件逻辑:and
Flows 中的 and_ 函数允许您监听多个方法,并且只有当所有指定方法都发出输出时才触发监听器方法。
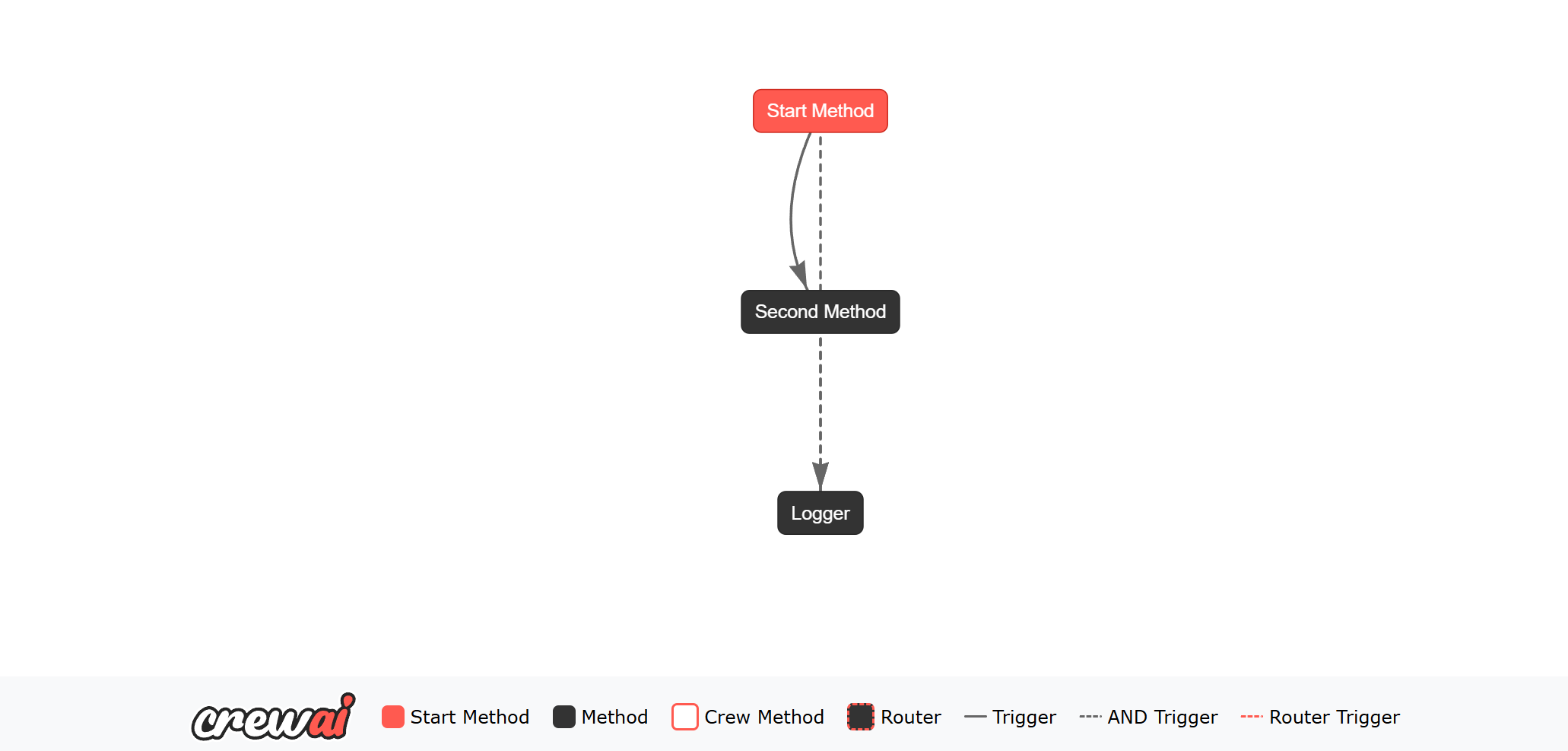
logger 方法仅当 start_method 和 second_method 都发出输出时才会被触发。and_ 函数用于监听多个方法,并且只有当所有指定方法都发出输出时才触发监听器方法。路由器
Flows 中的@router() 装饰器允许您根据方法的输出定义条件路由逻辑。您可以根据方法的输出指定不同的路由,从而动态控制执行流程。
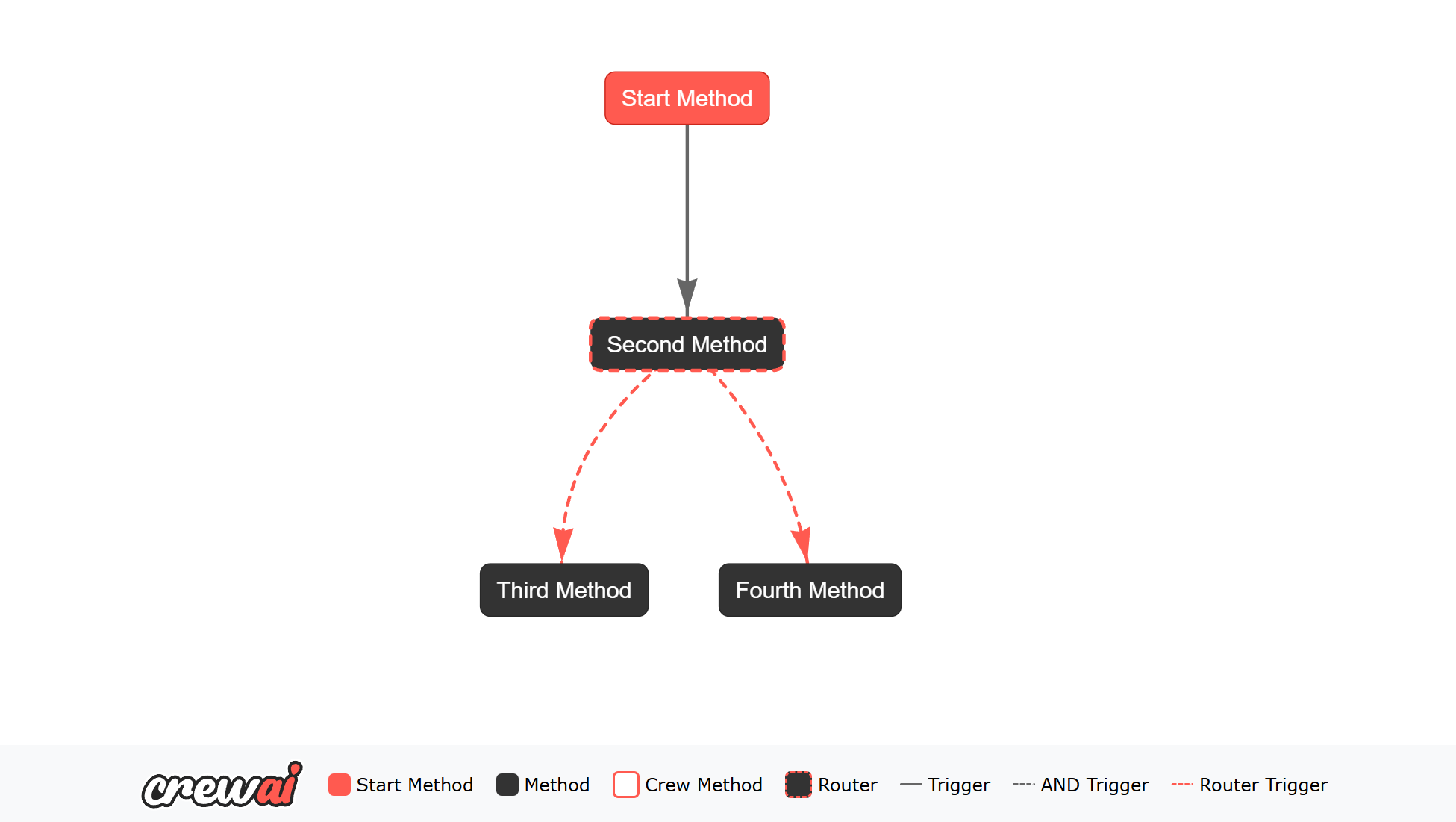
start_method 生成一个随机布尔值并将其设置在状态中。second_method 使用 @router() 装饰器根据布尔值定义条件路由逻辑。如果布尔值为 True,则方法返回 "success";如果为 False,则方法返回 "failed"。third_method 和 fourth_method 监听 second_method 的输出并根据返回的值执行。 当您运行此流程时,输出将根据 start_method 生成的随机布尔值而改变。向流程添加智能体
智能体可以无缝地集成到您的流程中,当您需要更简单、更集中的任务执行时,它提供了一个轻量级的替代方案,而不是完整的智能体组。以下是一个在流程中使用智能体进行市场研究的示例: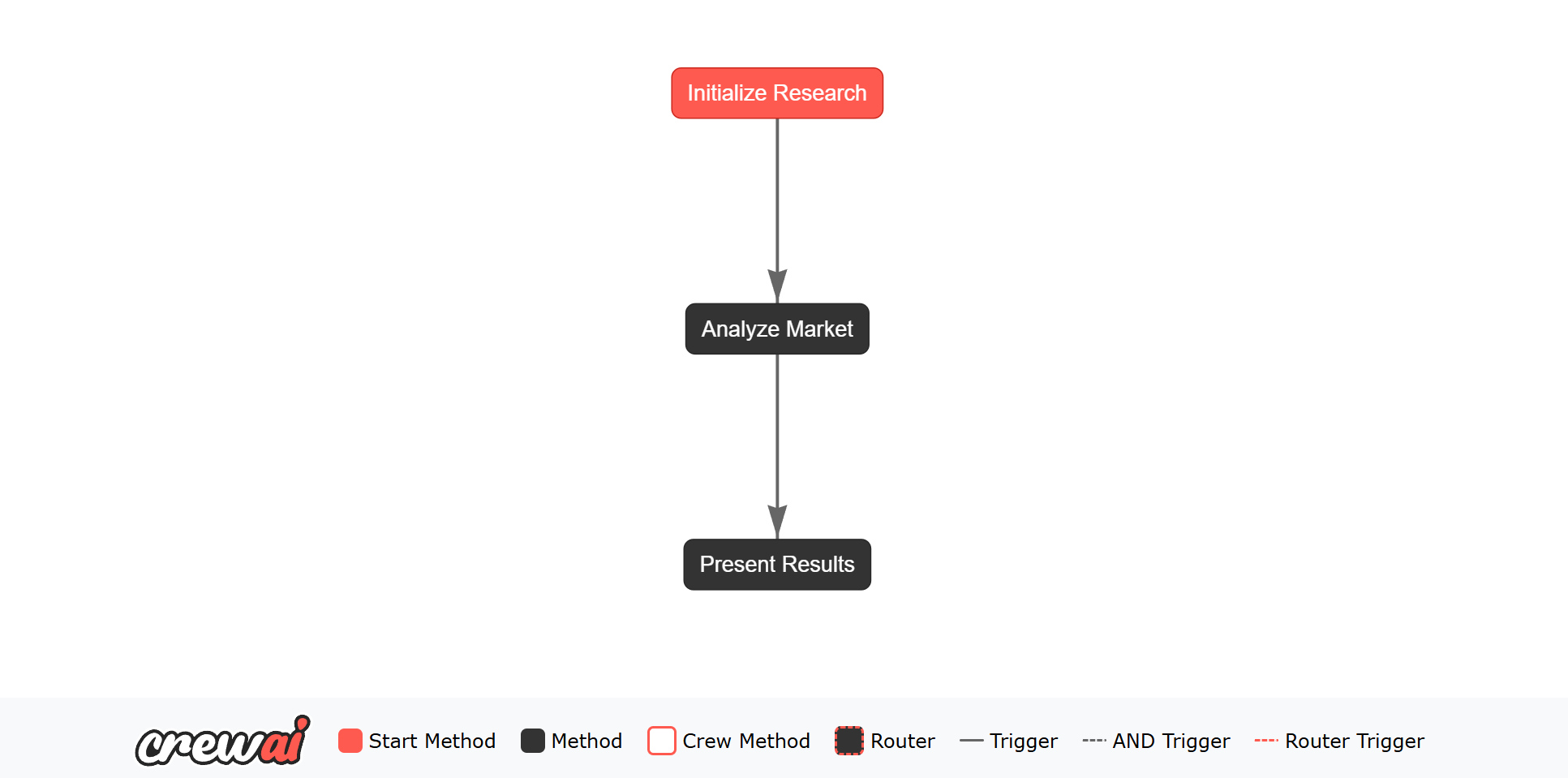
-
结构化输出:使用 Pydantic 模型定义预期的输出格式(
MarketAnalysis),确保了整个流程中的类型安全和结构化数据。 -
状态管理:流程状态(
MarketResearchState)在步骤之间保持上下文,并存储输入和输出。 -
工具集成:智能体可以使用工具(如
WebsiteSearchTool)来增强其功能。
向流程添加智能体组
在 CrewAI 中创建包含多个智能体组的流程很简单。 您可以通过运行以下命令生成一个包含所有必要骨架的新 CrewAI 项目,以创建具有多个智能体组的流程:poem_crew 的预构建智能体组,它已经可以工作了。您可以通过复制、粘贴和编辑此智能体组来创建其他智能体组作为模板。
文件夹结构
运行crewai create flow name_of_flow 命令后,您将看到类似于以下内容的文件夹结构
| 目录/文件 | 描述 |
|---|---|
name_of_flow/ | 流程的根目录。 |
├── crews/ | 包含特定智能体组的目录。 |
│ └── poem_crew/ | “poem_crew”的目录,包含其配置和脚本。 |
│ ├── config/ | “poem_crew”的配置文件目录。 |
│ │ ├── agents.yaml | 定义“poem_crew”智能体的 YAML 文件。 |
│ │ └── tasks.yaml | 定义“poem_crew”任务的 YAML 文件。 |
│ ├── poem_crew.py | “poem_crew”功能的脚本。 |
├── tools/ | 流程中使用的其他工具的目录。 |
│ └── custom_tool.py | 自定义工具实现。 |
├── main.py | 运行流程的主脚本。 |
├── README.md | 项目描述和说明。 |
├── pyproject.toml | 项目依赖项和设置的配置文件。 |
└── .gitignore | 指定在版本控制中忽略的文件和目录。 |
构建您的智能体组
在crews 文件夹中,您可以定义多个智能体组。每个智能体组都有自己的文件夹,其中包含配置文件和智能体组定义文件。例如,poem_crew 文件夹包含:
config/agents.yaml:定义智能体组的智能体。config/tasks.yaml:定义智能体组的任务。poem_crew.py:包含智能体组定义,包括智能体、任务和智能体组本身。
poem_crew 来创建其他智能体组。
在 main.py 中连接智能体组
main.py 文件是您创建流程并将智能体组连接在一起的地方。您可以通过使用 Flow 类和装饰器 @start 和 @listen 来定义流程的执行流。 以下是如何在 main.py 文件中连接 poem_crew 的示例:代码
PoemFlow 类定义了一个流程,该流程生成句子计数,使用 PoemCrew 生成诗歌,然后将诗歌保存到文件中。通过调用 kickoff() 方法启动流程。plot() 方法将生成 PoemFlowPlot。 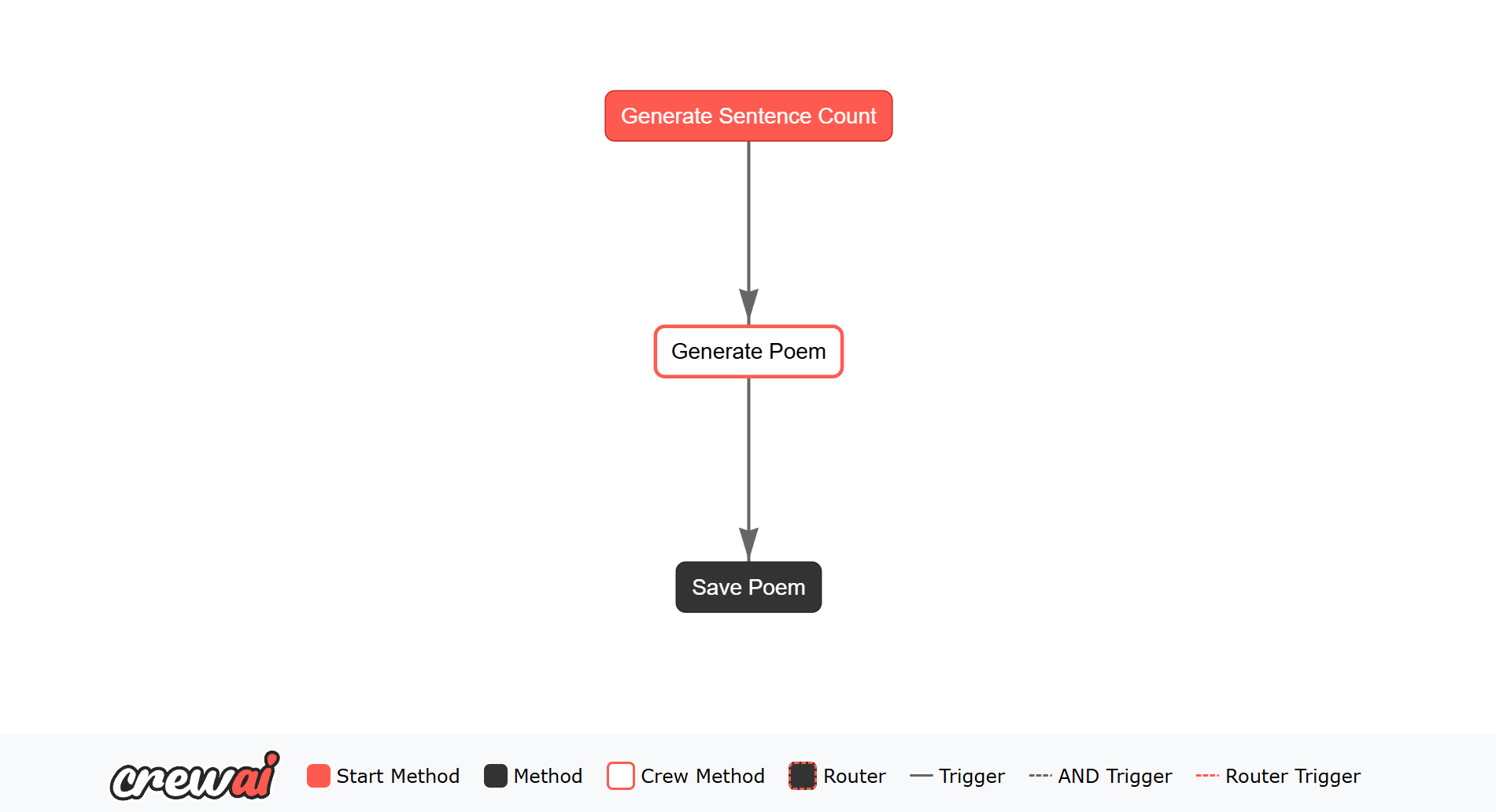
运行流程
(可选)在运行流程之前,您可以运行以下命令安装依赖项绘制流程图
可视化您的 AI 工作流可以为流程的结构和执行路径提供有价值的见解。CrewAI 提供了一个强大的可视化工具,允许您生成流程的交互式图表,从而更轻松地理解和优化您的 AI 工作流。什么是图表?
CrewAI 中的图表是 AI 工作流的图形表示。它们显示了各种任务、它们的连接以及它们之间的数据流。这种可视化有助于理解操作序列,识别瓶颈,并确保工作流逻辑符合您的期望。如何生成图表
CrewAI 提供了两种方便的方法来生成流程图选项 1:使用 plot() 方法
如果您直接使用流程实例,可以通过在流程对象上调用 plot() 方法来生成图表。此方法将创建一个包含流程交互式图表的 HTML 文件。
代码
my_flow_plot.html 的文件。您可以在网页浏览器中打开此文件以查看交互式图表。
选项 2:使用命令行
如果您在一个结构化的 CrewAI 项目中工作,您可以使用命令行生成图表。这对于您想要可视化整个流程设置的更大项目特别有用。plot() 方法。该文件将保存到您的项目目录中,您可以在 Web 浏览器中打开它以探索流程。
理解图表
生成的图表将显示代表流程中任务的节点,并带有指示执行流程的有向边。该图表是交互式的,允许您放大和缩小,并将鼠标悬停在节点上以查看更多详细信息。 通过可视化您的流程,您可以更清楚地了解工作流的结构,从而更容易调试、优化并向他人传达您的 AI 过程。结论
绘制流程图是 CrewAI 的强大功能,可增强您设计和管理复杂 AI 工作流的能力。无论您选择使用plot() 方法还是命令行,生成图表都将为您提供工作流的视觉表示,有助于开发和演示。
后续步骤
如果您有兴趣探索更多流程示例,我们会在示例库中提供各种建议。这里有四个特定的流程示例,每个都展示了独特的用例,以帮助您将当前问题类型与特定示例进行匹配- 电子邮件自动回复流程:此示例演示了一个无限循环,其中后台作业持续运行以自动回复电子邮件。这是一个需要重复执行而无需手动干预的任务的绝佳用例。查看示例
- 潜在客户评分流程:此流程展示了如何添加人工反馈并使用路由器处理不同的条件分支。这是一个如何在工作流中整合动态决策和人工监督的绝佳示例。查看示例
- 写书流程:此示例擅长将多个智能体组链接在一起,一个智能体组的输出被另一个智能体组使用。具体来说,一个智能体组概述整本书,另一个智能体组根据大纲生成章节。最终,所有内容都连接起来以生成一本完整的书。此流程非常适合需要协调不同任务的复杂多步骤流程。查看示例
- 会议助理流程:此流程演示了如何广播一个事件以触发多个后续操作。例如,会议结束后,流程可以更新 Trello 面板、发送 Slack 消息并保存结果。这是一个处理单个事件的多个结果的绝佳示例,使其成为全面任务管理和通知系统的理想选择。查看示例
运行流程
运行流程有两种方式使用流程 API
您可以通过创建流程类实例并调用kickoff() 方法来以编程方式运行流程。
流式流程执行
为了实时查看流程执行情况,您可以启用流式传输以接收实时生成的输出使用 CLI
从版本 0.103.0 开始,您可以使用crewai run 命令运行流程
type = "flow" 设置),并相应地运行它。这是从命令行运行流程的推荐方式。 为了向后兼容,您也可以使用:crewai run 命令现在是首选方法,因为它适用于智能体组和流程。